
仕事で、データを処理・分析・解析する必要があるといった場合に、どのような方法を用いるでしょうか。使用用途に合わせてAPIを利用してデータを取得したり、スクレイピングでデータ取得をしたりするようなケースもあるかもしれません。
ここでは一例としてPythonライブラリを使ったスクレイピングについて考えたいと思います。
取得元のサイトがスクレイピングを禁止していたり、取得するデータの著作権の問題やサーバーへの負荷をかけない等、使用するにあたって注意する点もありますが、Webサイトやニュースメディアからの記事などの最新情報を自動で収集することができるというのは、非常に便利なツールといって良いでしょう。
今回は、Pythonライブラリ「Scrapy」を用いたスクレイピングの方法について、Webサイトからデータを抽出する例を使って説明していきたいと思います。

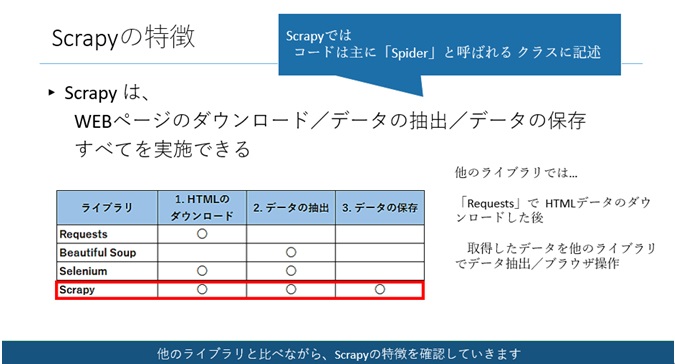
Scrapyの特徴
Scrapyとは、スクレイピングに関するPythonライブラリの1つです。他にも「Beautiful Soup」や「Selenium」などのライブラリでスクレイピングをしたことがある方もいらっしゃるかもしれません。
WEBページのダウンロード/データの抽出/データの保存すべてをScrapyで実施できるという特徴があります。
それでは、実際にVisual Studio CodeにScrapyをインストールしてから、スクレイピングの練習をしていきましょう。
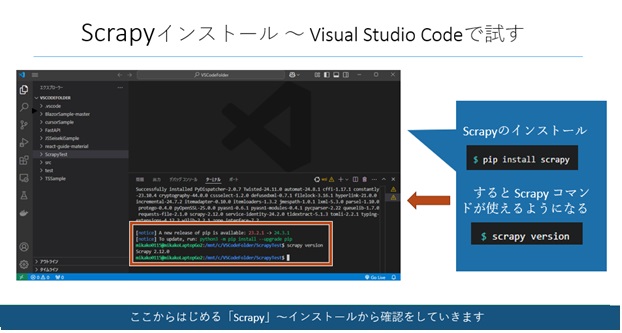
Scrapyのインストール
Visual Studio Codeのターミナルで「$pip install scrapy」コマンドを打ちます。
$pip install scrapy
そうすると、Scrapyコマンドが使えるようになりますので、「$scrapy version」のコマンドで実際にバージョンが表示されるかを確認しましょう。
$scrapy version
Scrapyのインストールが終わりましたら、
実際にサンプルの書籍紹介ページからデータ取得してみましょう。
それでは、Scrapyでプロジェクト作成後、Spiderにコードを記述してデータ抽出までしていきましょう

プロジェクトの作成とSpiderの編集、実行
・プロジェクトの作成
「Scrapy startproject プロジェクト名」のコマンドを打ちます。
すると、↓のような構成のフォルダが作成されます。
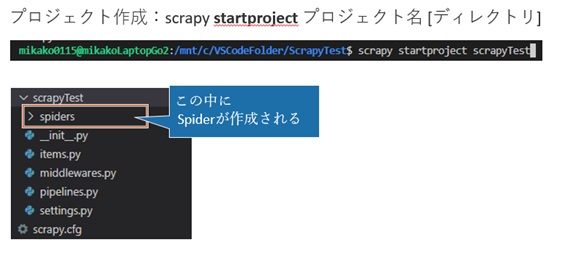
プロジェクト作成後には、まだ「spiders」フォルダの中には何もソースは入っていません。
そこで、次の「scrapy genspider スパイダー名 URL 」のコマンドを打ち、spiderを作成していきます。
$scrapy genspider books_basic https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html
上記のコマンドを打つことで、「spiders」フォルダの中に「books_basic.py」のソースが作成されます。

「books_basic.py」のソースのparseメソッドを編集後、実行していきましょう。
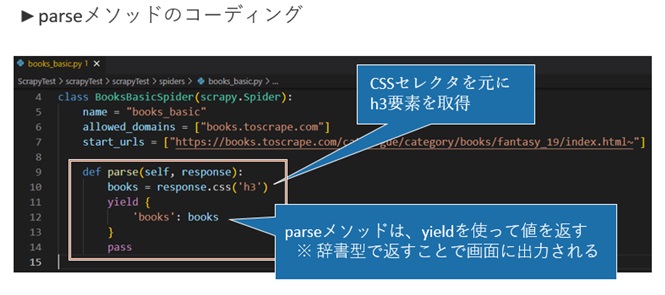
parseメソッドにwebサイトからデータを抽出する際の条件を記載して実行することで、
requestをキャッチしてresponseを取得することができます。
ここでは、CSSセレクタを元にh3要素を取得し、yieldを使って取得した内容を画面に出力していきます。
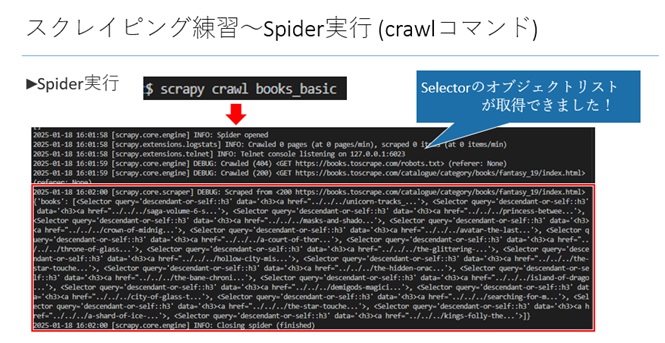
実行することで実際にセレクトのオブジェクトリストを取得できると思います。
parseメソッドに記載するデータ抽出する条件を変えることで、取得したいデータを抽出することができると思います。用途に合わせてspiderの記載を変えてみてください。
業務でPythonを使ってツールを作ったり、自動化処理を記述したりする機会がある方もいらっしゃると思います。自身のPCでVisual Studio Codeを使って簡単に今回のサンプルを試すことができますので、この機会にPythonに触れる時間を作っていただけると嬉しい限りです。
以上となります。
参考サイト:
https://ai-inter1.com/python-scrapy-for-begginer/#rtoc-2




