
ツールを導入・運用する為、VBAのような他のプログラミング言語を使って開発したことがあるいう方もいらっしゃると思います。使用用途に合わせてデータ処理・分析・解析する際、APIを利用してデータを取得したり、スクレイピングでデータ取得をしたいケースなどもあるかもしれません。
取得元のサイトがスクレイピングを禁止していたり、取得するデータの著作権の問題やサーバーへの負荷をかけない等、使用するにあたって注意する点もありますが、株価の変動やニュースメディアからの記事などの最新情報を自動で収集することができるというのは、非常に便利なツールといって良いでしょう。
今回は、Yahooニュースの見出しとURLの内容を取得する例を考えたいと思います。
ここでは、PySimpleGUIライブラリを使用して以下のような画面レイアウトを使用しますが、詳しく知りたいという方は、過去のブログを参考にしてみてください。では、サンプルコードを実行してみましょう。
Contents
PySimpleGUIで画面レイアウト作成
問題1:PySimpleGUIのサンプル実行 ~ 画面レイアウトの作成
以下のサンプルコードを読み、Scrapingで読み込む内容を出力する画面サンプルを実行してください。
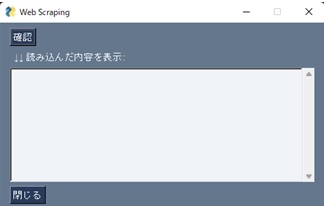
*仕様:確認ボタンを押下後に、Web Scrapingで読み込んだ内容(Yahooニュースの見出しとURL)を表示する
・インストール
pipというPythonのパッケージ管理ツールを使って、「PySimpleGUI」をインストールします。
pip install PySimpleGUI
► layout_PySimpleGUI.py
import PySimpleGUI as sg
layout = [
[sg.Button('確認')],
[sg.Text(" ↓↓ 読み込んだ内容を表示:")],
[sg.Multiline(default_text='', size=(60,10), border_width=2, key='tb1')],
[sg.Button('閉じる')]
]
window = sg.Window("Web Scraping", layout)
# イベントループ
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == '閉じる':
break
elif event == '確認':
# 処理の内容を記載
# sg.popup('処理内容の実装前')
window['tb1'].print('表示する内容:処理の実装前')
window.close()
それではBeautifulSoupの使い方の基礎を確認していきます。
Webスクレイピングの基礎~Beautiful Soupの基本的な使い方
BeautifulSoupとは、HTMLやXMLからデータを抽出する為のPythonのライブラリです。
HTMLを整形する前段として、「Requests」というHTTP通信ができるモジュールを利用して、HTMLのデータをスクレイピングします。
スクレイピングの手順
以下のような手順で、スクレイピングを行います。
Jupyter Notebookなどで動作確認しながら、実装をしていきましょう。
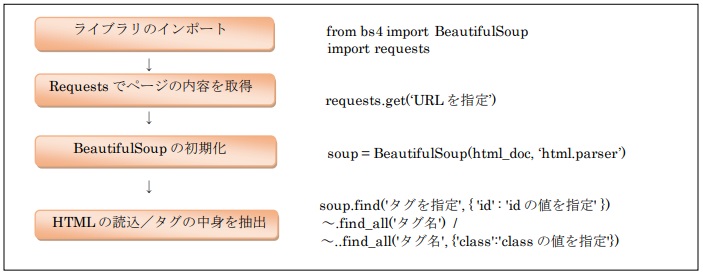
スクレイピングをする為に、事前にrequestsとBeautifulSoupをインストールします。
<requestsのインストール> : pip install requests
<BeautifulSoupのインストール>: pip install beautifulsoup4
それでは手順に従って、Yahoo!ニュースの主要見出しとURLの情報を取得する方法をみていきましょう。
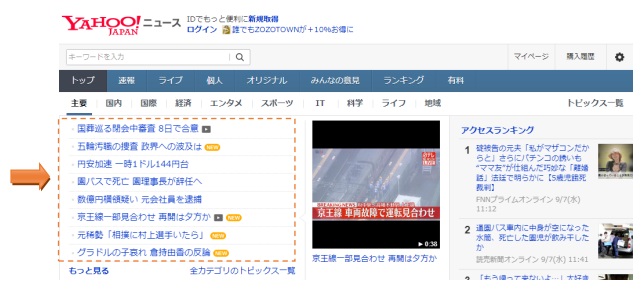
Yahoo!ニュースの主要見出しとURLの情報を取得する方法
● インポート
インストールしたrequestsとBeautifulSoupのインポート文を記載します。
import requests from bs4 import BeautifulSoup
● Requestsでページの内容を取得
まず、requestsを利用してYahoo!ニューストップページの全ての情報を取得します。
URL = "https://www.yahoo.co.jp/" item = requests.get(URL)
requests.get(URL)と書くことで、URLで指定したページの内容を取得することができます。
● BeautifulSoupの初期化
htmlデータをプログラムで扱えるようなデータ構造に整形します。
soup = BeautifulSoup(item.text, "html.parser")
● HTMLの読込/タグの中身を抽出
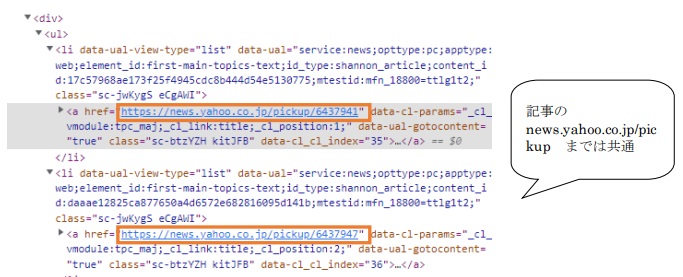
主要見出しとURLの情報を抽出します。
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for data in data_list:
print(data.span.string)
print(data.attrs["href"])
ここで、読み込んだHTMLの中身を抽出します。「re.compile」とは正規表現パターンを利用することを意味します。find_allメソッドを利用して、抽出ができるという点は押さえておきましょう。
抽出の方法についての詳細は各自必要に応じて調べてみてください。
► 実装例
import requests
from bs4 import BeautifulSoup
import re
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
item = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(item.text, "html.parser")
# ヤフーニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for data in data_list:
print(data.span.string)
print(data.attrs["href"])
問題2【課題】:Yahooニュースの主要見出しとURLの情報を抽出
問題1にて作成した以下の画面レイアウトにて
確認ボタンを押下した際に、Yahooニュースの主要見出しとURLの情報が表示されるよう実装をしてください。
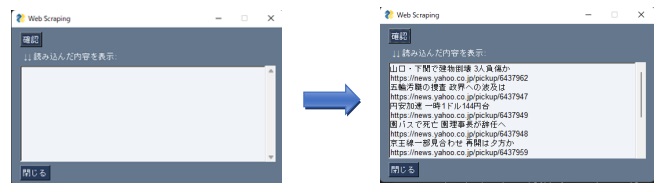
参考URL:
PythonでITニュースサイトの見出しをWebスクレイピング
https://qiita.com/y-araki-qiita/items/c9db8c18998e6cb10de7
【Webスクレイピング入門】ヤフーニュース の見出しとURLを取得する方法
https://rurukblog.com/post/python-webscraping-ynews/
====================================
業務でPythonを使ってツールを作ったり、自動化処理を記述したりする機会がある方もいらっしゃると思います。自身のPCでVisual Studio Codeを使って簡単に今回のサンプルを試すことができますので、この機会にPythonに触れる時間を作っていただけると嬉しい限りです。
以上となります。



